

The Chinese AI company DeepSeek has developed a novel open-source language AI model, DeepSeek R-1, which has sparked numerous discussions. Certain users assert that it matches or surpasses OpenAI’s o1 model regarding reasoning abilities.
DeepSeek is available at no cost, which is excellent for users but prompts some enquiries. Given the significant rise in users, what strategies do they employ to handle server expenses?
Ultimately, the costs associated with hardware operations are unlikely to be low, aren’t they?
The sole rational conclusion in this situation is data. Data serves as the essential foundation for AI models. They are likely gathering user data to monetise their model in the future.
If you have concerns about data privacy but wish to use R1 without disclosing your information, the optimal approach is to operate the model locally.
What is DeepSeek R-1?
Recently, Deepseek R-1 was unveiled as an open-source model, allowing anyone to access the base code, modify it, and customise it to meet their specific requirements.
Technically, the Deepseek R-1, also known as R1, builds upon a substantial base model known as DeepSeek-V3. The laboratory subsequently enhanced this model through a blend of supervised fine-tuning (SFT) using high-quality human-labeled data and reinforcement learning (RL).
The outcome is a chatbot capable of managing intricate queries, revealing the reasoning behind complicated questions (occasionally with greater clarity than other models), and even showcasing code within the chat interface for swift testing.
This is truly remarkable, particularly for an open-source model.
How to launch it locally
To operate DeepSeek R-1 on your local machine, we will use the Ollama tool.
Ollama is a free and open-source tool for running large language models (LLMs) directly on computers. It is available for macOS, Linux, and Windows.
Visit the official Ollama website and select the ‘Download’ button. Set it up on your computer.
To verify that the installation was successful, open a terminal and run the following command:
ollama -v
ollama -v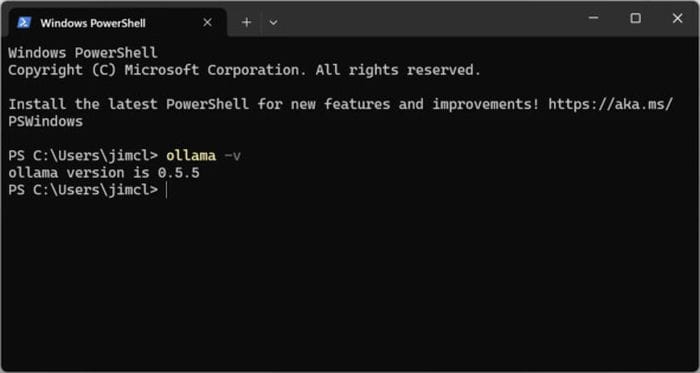
Instead of an error, you should see the Ollama version number.
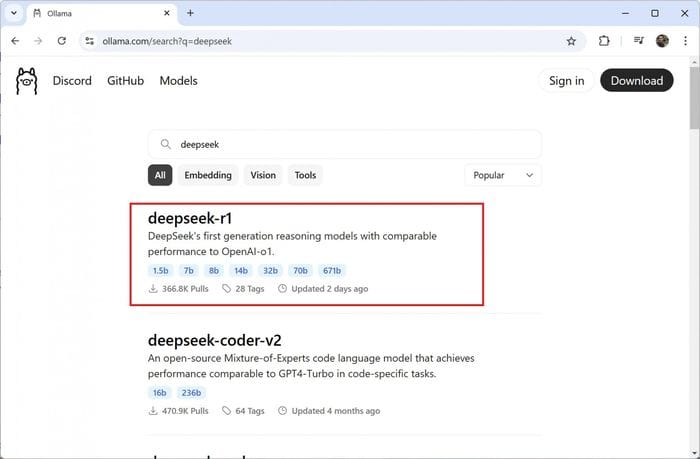
On the Models tab, search for the keyword ‘deepseek’; you should see ‘deepseek-r1’ as the first item in the search list.
Click on it and go to the Models section, where several model sizes range from 1.5 billion to 671 billion parameters. Typically, larger models require more powerful GPUs to run.
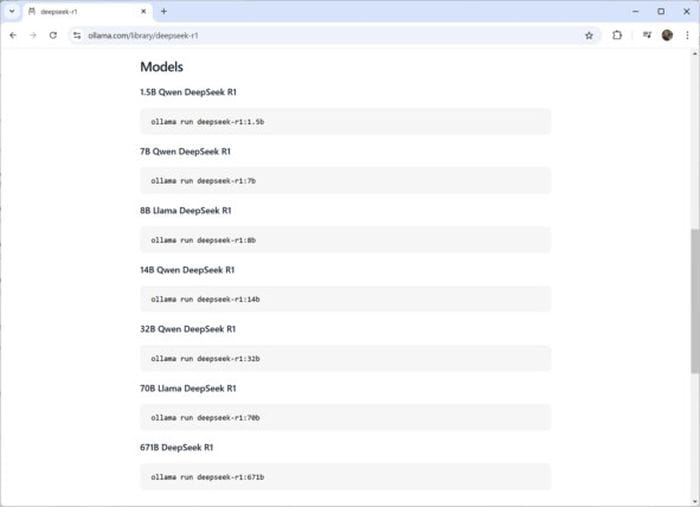
Smaller models, such as the 8 billion parameter version, can handle GPUs with 8 GB of video memory. Larger models require significantly more resources (see ‘VRAM and GPU Requirements’ below).
To load and run a model with 8 billion parameters, run the following command:
ollama run deepseek-r1:8bThis will start downloading the model (about 4.9 GB). Before proceeding, make sure you have enough space on your disc.
Once you download the model, your computer will run it locally, and you will be able to communicate with it immediately.
Let’s test it with this prompt example:
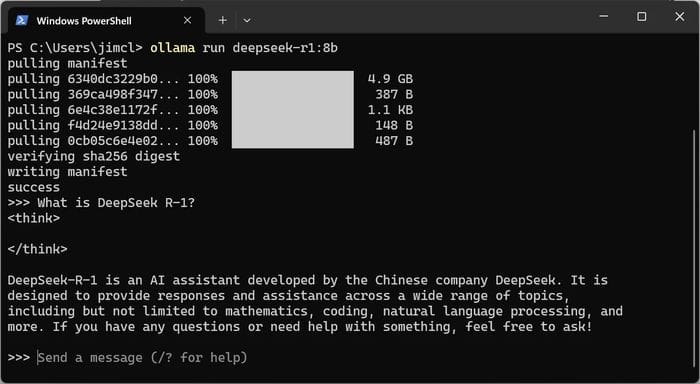
- Prompt: What is DeepSeek R-1?
- The Chinese company DeepSeek developed DeepSeek-R-1, an AI assistant. It is designed to provide answers and help on a wide range of topics, including but not limited to math, coding, natural language processing, and more. If you have questions or need help, feel free to ask!
Great. It’s fast and works even if I disconnect my laptop from Wi-Fi. However, even with an internet connection, you cannot access the network.
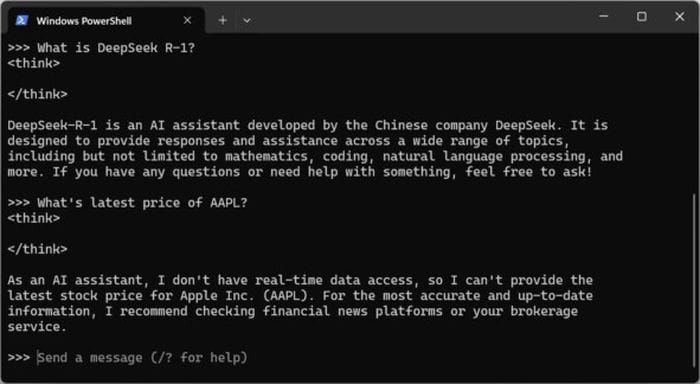
- Prompt: What is the latest price of AAPL?
- Answer: As an AI assistant, I do not have access to real-time data, so I cannot provide the latest information on the Apple Inc. (AAPL) stock price. I recommend consulting financial news platforms or your broking for the most accurate and up-to-date information.
Other things Ollama can do:
- Run LLMs locally, including LLaMA2, Phi 4, Mistral, and Gemma 2.
- It allows users to create and share their own LLMs.
- Combines model weights, configuration, and data into a single package
- It optimises installation and configuration details, including GPU usage.
GPU and VRAM Requirements
The VRAM requirements for DeepSeek-R1 depend on factors such as model size, number of parameters, and quantisation methods. Below is a detailed overview of the VRAM requirements for DeepSeek-R1 and its distilled models, along with recommended GPUs:
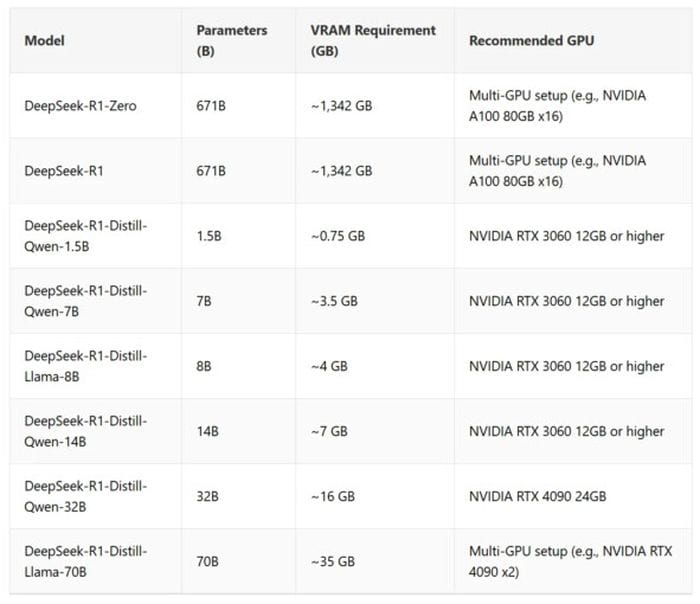
Keynotes on VRAM usage:
- Spread-out GPU configuration for big models: Running DeepSeek-R1-Zero and DeepSeek-R1 needs a lot of VRAM, so for the best performance, spread-out GPU configurations like NVIDIA A100 or H100 in multi-GPU systems are required.
- Distilled models are optimised to run on a single GPU with less VRAM, starting at 0.7 GB.
- Additional Memory Usage: Activations, buffers, and batch processing tasks can use additional memory.
Why run it locally?
Of course, the web chatbot and mobile app for DeepSeek are free and incredibly convenient. You don’t have to set anything up, and features like DeepThink and web search are already built into them. But there are a few reasons why a local installation might be a better choice:
Privacy
DeepSeek’s servers process your requests and attachments when using the web version or app. What happens to this data? We don’t know. When you run the model locally, your data remains on your computer, giving you complete control over your privacy.
Offline access
Running the model locally means you don’t need an internet connection. Whether travelling, dealing with unstable Wi-Fi, or preferring to work offline, a local installation will allow you to use DeepSeek anytime and anywhere.
Protection against future monetisation
DeepSeek’s services may be free right now, but that’s unlikely to last forever. Eventually, they will want to monetise the model, and usage restrictions or subscription fees may follow. By running the model locally, you can bypass these restrictions entirely.
Flexibility
You can customise the local version beyond the default settings. Do you want to refine the model, integrate it with other tools, or create your own interface? Thanks to its open-source nature, DeepSeek R-1 gives you limitless possibilities.
How DeepSeek manages user data is not apparent right now. If you are not very worried about data privacy, you would be better off using a web or mobile app, as they have capabilities such as DeepThink and online searching and are simpler to use. However, if you are concerned about the privacy of your data, you should consider using a local model.
Even on somewhat low-powered systems, DeepSeek models operate effectively. While bigger models like DeepSeek-R1-Zero demand distributed GPUs, the distilled variants function well on a single GPU with significantly less need.







